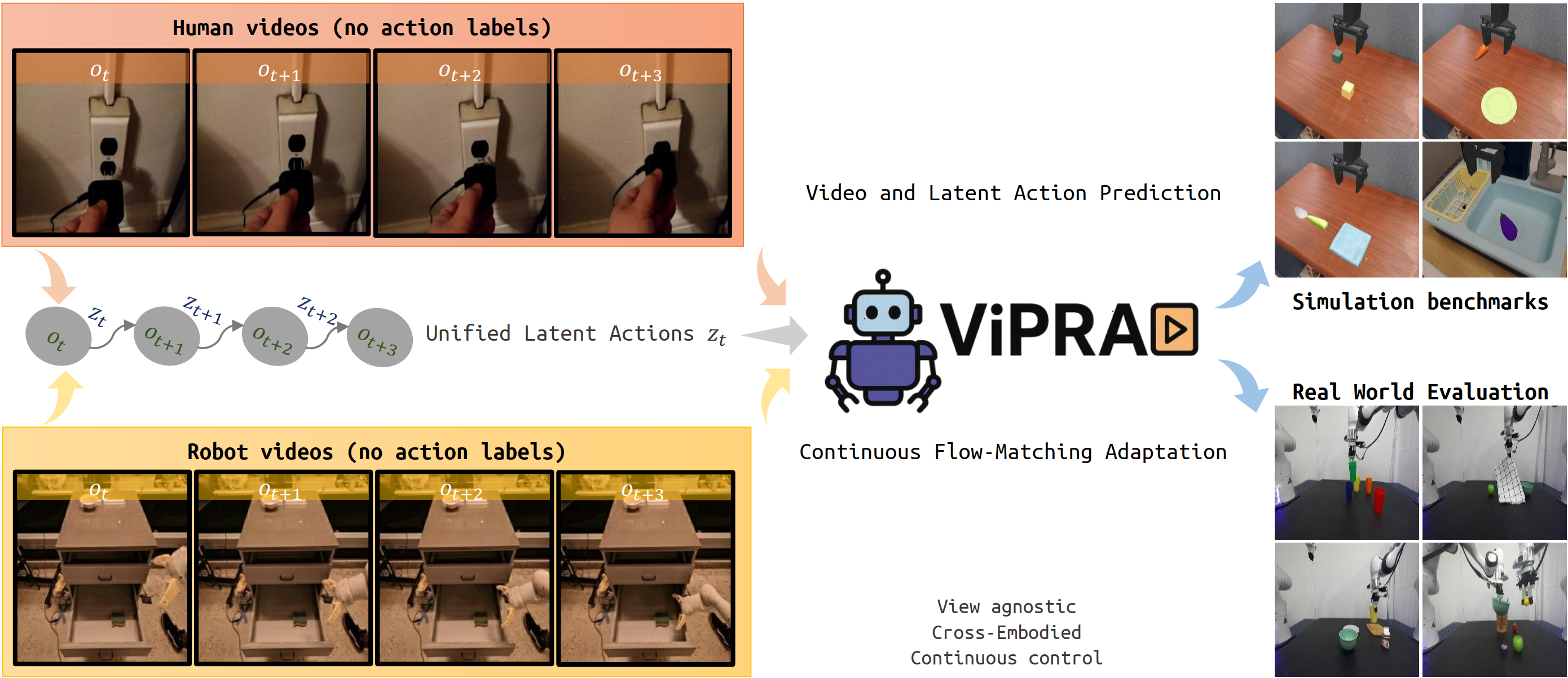
Can we turn a video prediction model into a robot policy? Videos, including those of humans or teleoperated robots, capture rich physical interactions. However, most of them lack labeled actions, which limits their use in robot learning. We present Video Prediction for Robot Actions (ViPRA), a simple pretraining-finetuning framework that learns continuous robot control from these actionless videos. Instead of directly predicting actions, we train a video-language model to predict both future visual observations and motion-centric latent actions, which serve as intermediate representations of scene dynamics. We train these latent actions using perceptual losses and optical flow consistency to ensure they reflect physically grounded behavior. For downstream control, we introduce a chunked flow-matching decoder that maps latent actions to robot-specific continuous action sequences, using only 100 to 200 teleoperated demonstrations. This approach avoids expensive action annotation, supports generalization across embodiments, and enables smooth, high-frequency continuous control via chunked action decoding. Unlike prior latent action works that treat pretraining as autoregressive policy learning, ViPRA explicitly models both what changes and how. Our method outperforms strong baselines, with a 16% gain on the SIMPLER benchmark and a 13% improvement across real world manipulation tasks.
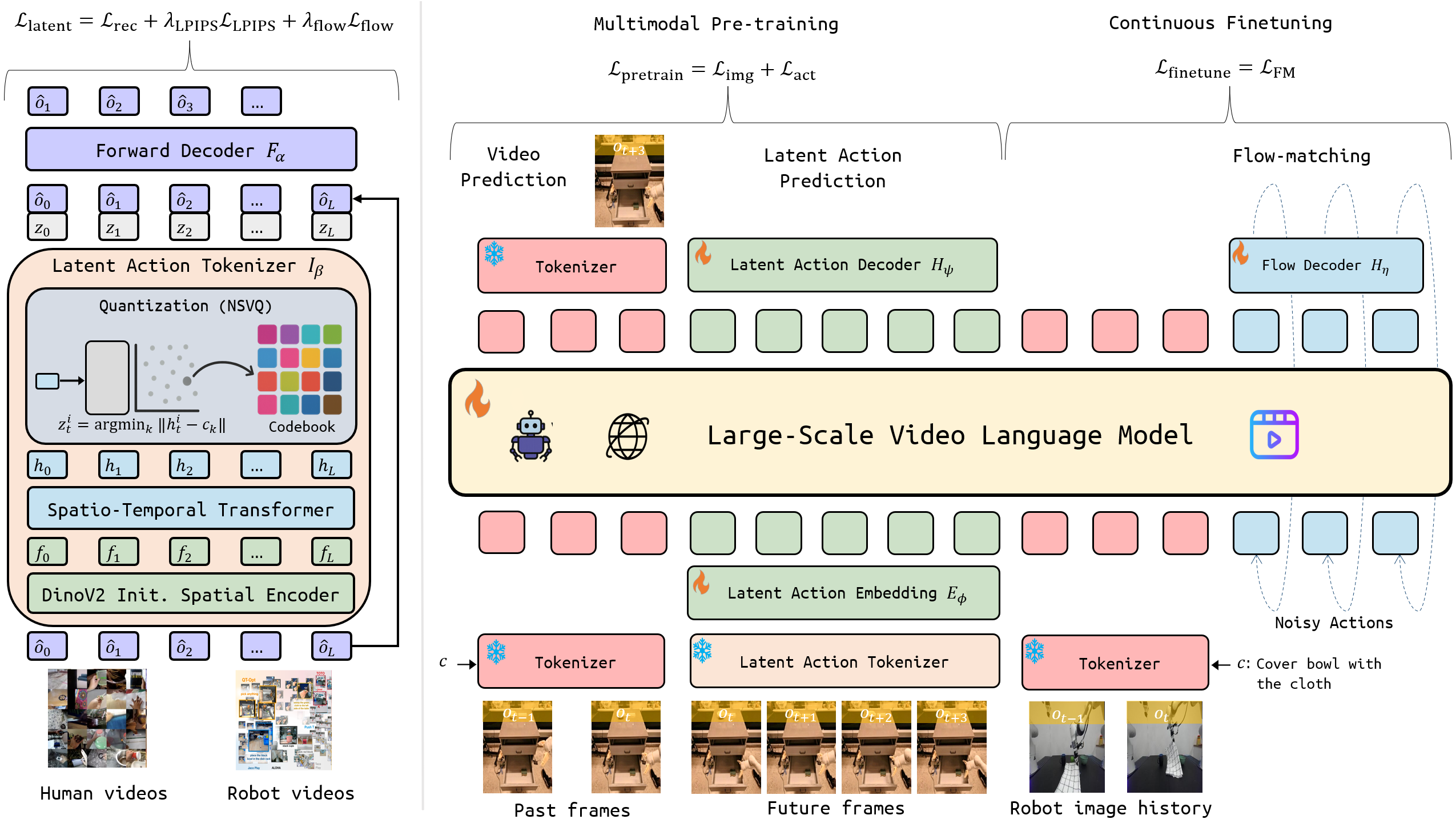
ViPRA is a scalable pretraining-finetuning framework that adapts a video-language model into robot control policies without requiring any action labels during pretraining. It begins by extracting fine motion-centric latent actions: discrete, temporally grounded representations of motion learned via a neural quantization bottleneck. These latent actions are trained using reconstruction, perceptual and optical flow consistency losses to capture meaningful scene dynamics.
A video-language model is then pretrained to jointly predict future image observations and these latent actions conditioned on past image history and a natural language task prompt. This enables the model to reason about both what changes in the scene and how it changes, without ever observing real robot actions.
Finally, we finetune the model on a small number of real-world robot demonstrations using a flow-matching decoder that maps latent actions to continuous action chunks to enable high-frequency reactive control.
ViPRA's latent action tokenizer learns motion-centric dynamics by encoding transferable motion semantics directly from video, thus capturing how objects move in a scene. Injecting latents from one clip into another can therefore change the motion while keeping the scene intact—for instance, turning a downward trajectory into upward movement, or reversing rightward motion to the left. These cross-video transfers highlight that ViPRA's latent codes reflect meaningful, dynamics-aware behavior.


Upward-motion latents flips a downward-moving clip into upward motion.


Leftward-motion latents flips a rightward-moving clip into leftward motion.
We evaluate ViPRA on a Franka Panda robot across diverse real-world manipulation tasks, including pick and place, covering, and stacking. Despite being trained with limited action-labeled data, it performs smooth and reliable behaviors, often retrying failed grasps. ViPRA generalizes to novel objects and visual variations, demonstrating robustness beyond the training distribution.
ViPRA generalizes to novel objects and visual variations, despite never observing them during pretraining or finetuning.
ViPRA shows robust recovery behavior. It can retry failed grasps and adapt to external perturbations, even when objects are moved during execution.
ViPRA uses action chunking with a flow-matching decoder to generate smooth, continuous action sequences. It reduces inference lag with KV caching to support high-frequency reactive robot control at up to 20 Hz with 14-action chunk length.
Bimanual tasks require precise coordination across both arms, making them significantly harder than single-arm manipulation. ViPRA controls all 14 degrees of freedom using a single vision-language policy, executing smooth, synchronized behaviors from just a monocular camera and task prompt.
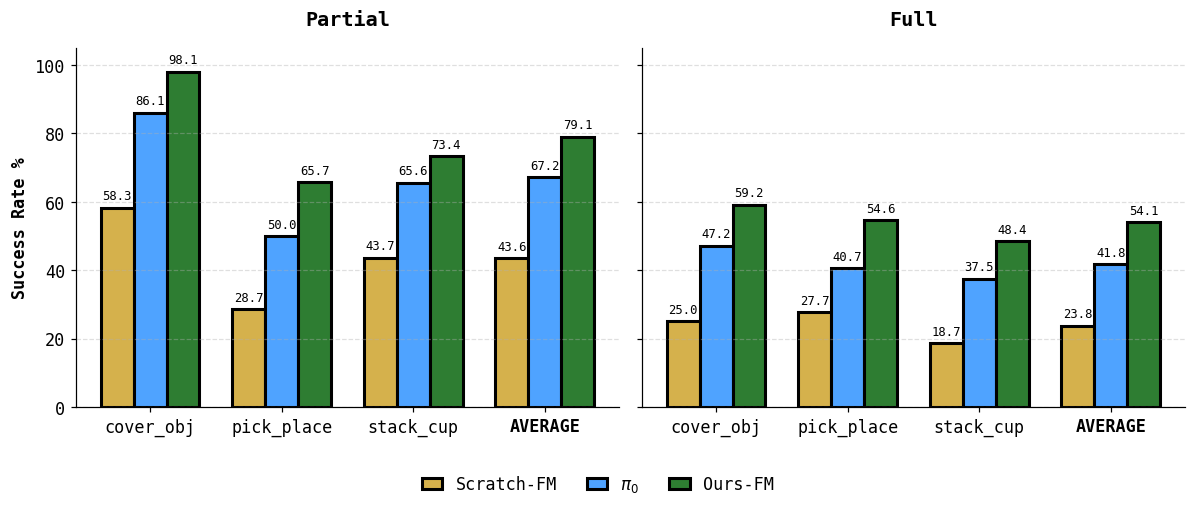
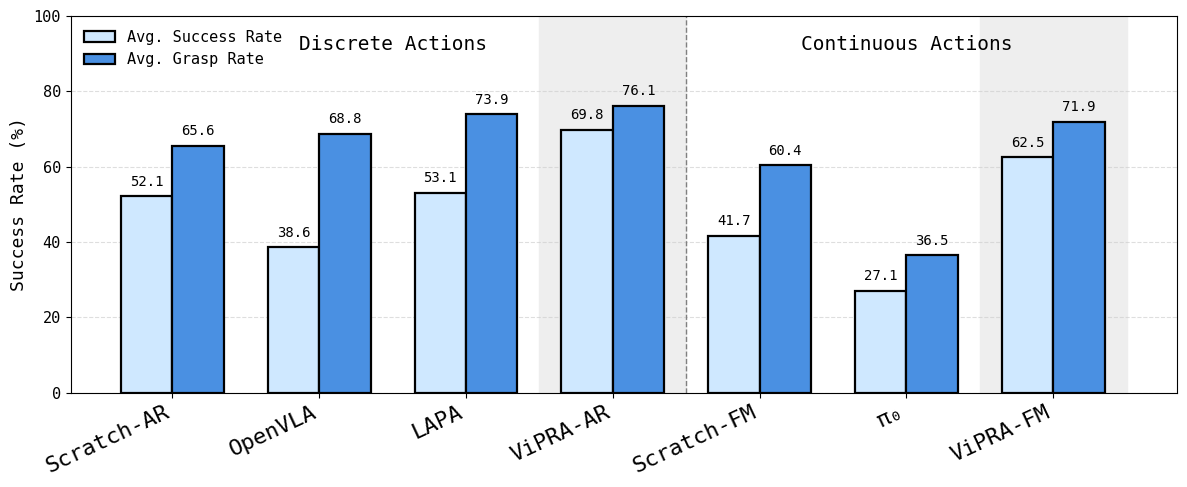
We evaluate ViPRA on the SIMPLER benchmark, a suite of simulated tasks built to test generalist robot control across diverse goals and object types. ViPRA outperforms all prior baselines in both discrete and continuous control settings.
In simulation, our discrete variant ViPRA-AR achieves the highest success rate—showing that discretized action prediction in an autoregressive manner can be very effective in low-noise, fully observed environments. Our continuous model, ViPRA-FM, also outperforms all other baselines, both discrete and continuous, highlighting the strength of our video-based pretraining. Its slightly lower score compared to ViPRA-AR reflects the slower convergence typical of flow matching. ViPRA-FM is better suited for real-world deployment, where smoothness and robustness are critical.
We thank Jason Liu and Tony Tao for their assistance in conducting the robot experiments, and Jim Yang, Mohan Kumar Srirama, and Tal Daniel for helpful discussions and feedback. This work was supported in part by the Air Force Office of Scientific Research (AFOSR) under Grant No.~FA9550-23-1-0747 and by the Office of Naval Research (ONR) MURI under Grant No.~N00014-24-1-2748.
@misc{routray2025vipra,
title={ViPRA: Video Prediction for Robot Actions},
author={Sandeep Routray and Hengkai Pan and Unnat Jain and Shikhar Bahl and Deepak Pathak},
year={2025},
eprint={2511.07732},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2511.07732},
}